Taalas vs Nvidia vs Groq vs Cerebras: AI Inference Hardware Compared (2026)
A detailed comparison of AI inference hardware in 2026: Taalas HC1 (model-on-silicon), Nvidia H200/B200 (general GPU), Groq LPU, Cerebras wafer-scale, and SambaNova. Performance, cost, flexibility, and fine-tuning support compared.
The AI inference hardware market is fragmenting. For years, Nvidia GPUs were the only serious option for running large language models. In 2026, at least five fundamentally different approaches compete for inference workloads — each with different trade-offs between speed, cost, flexibility, and fine-tuning support.
This comparison breaks down what each approach offers and where it fits.
The Contenders
Nvidia: General-Purpose GPU
Approach: General-purpose GPUs with massive parallelism and large HBM (High Bandwidth Memory). The same hardware trains and serves models.
Current products: H100 (80GB HBM3), H200 (141GB HBM3e), B200 (192GB HBM3e)
Key strengths:
- Runs any model architecture, any size
- Full fine-tuning and inference on the same hardware
- Largest software ecosystem (CUDA, TensorRT, vLLM)
- Proven at scale across every major AI company
Key limitations:
- Expensive ($25,000–$40,000+ per GPU)
- High power consumption (700W+ per GPU)
- Per-user throughput is modest relative to specialized hardware
- Supply-constrained at the high end
Inference performance (Llama 3.1 8B): ~230 tokens/sec per user on H200
Groq: Language Processing Unit (LPU)
Approach: Custom-designed inference chips called Language Processing Units (LPUs). Optimized for sequential token generation with deterministic execution — no variable scheduling overhead.
Key strengths:
- Very fast per-user inference (~600 tokens/sec on Llama 8B class)
- Deterministic latency (no variable wait times)
- Designed specifically for autoregressive inference
- Available as a cloud API
Key limitations:
- Inference only — no training capability
- Limited to supported model architectures
- No hardware-level fine-tuning support
- Currently only available as cloud service
Cerebras: Wafer-Scale Engine
Approach: An entire silicon wafer as a single chip. The CS-3 contains 4 trillion transistors and 900,000 cores across a single wafer. Designed for both training and inference at extreme scale.
Key strengths:
- Massive on-chip memory eliminates memory bottleneck
- Fast inference (~2,000 tokens/sec per user on Llama 8B class)
- Can handle very large models on a single system
- Available as cloud inference API
Key limitations:
- Extremely expensive hardware
- Primarily available as managed service
- Wafer-scale manufacturing has lower yields
- No built-in LoRA/fine-tuning support at the hardware level
SambaNova: Reconfigurable Dataflow Architecture
Approach: Reconfigurable Dataflow Units (RDUs) that can be optimized for different model architectures. Designed to handle both training and inference.
Key strengths:
- Reconfigurable for different model architectures
- Handles training and inference
- Enterprise-focused with managed service offerings
- Supports multiple model sizes
Key limitations:
- Smaller ecosystem than Nvidia
- Limited public benchmark data compared to competitors
- Primarily enterprise/cloud deployment
Taalas: Model-on-Silicon (ASIC)
Approach: Hardwire a specific model's weights directly into an ASIC's transistors. Instead of loading weights from memory, the model is the chip. The HC1 is their first product, running Llama 3.1 8B.
Key strengths:
- Fastest per-user inference: ~17,000 tokens/sec
- Lowest cost per token: ~$0.0075/M tokens
- Lowest power consumption: 2.5 kW server
- LoRA adapter support for customization
- 20x lower build cost than GPU alternatives
Key limitations:
- Locked to a single base model (Llama 3.1 8B on HC1)
- Aggressive quantization (3-bit) introduces quality trade-offs
- Beta product — not yet available for on-premise purchase
- Cannot run different model architectures
Head-to-Head Comparison
| Nvidia H200 | Groq LPU | Cerebras CS-3 | SambaNova | Taalas HC1 | |
|---|---|---|---|---|---|
| Architecture | General GPU | Custom LPU | Wafer-scale | Dataflow RDU | Model-on-silicon ASIC |
| Tokens/sec/user (8B) | ~230 | ~600 | ~2,000 | ~800 (est.) | ~17,000 |
| Cost per 1M tokens | ~$0.50–2.00 | ~$0.05–0.27 | ~$0.10 | N/A (enterprise) | ~$0.0075 |
| Model flexibility | Any model | Multiple | Multiple | Multiple | Single + LoRA |
| Training support | Full | None | Full | Full | None (LoRA inference only) |
| LoRA fine-tuning | Full | No | No | No | Hardware-level LoRA |
| Power per unit | 700W+ | ~300W | High | Medium | ~250W per card |
| Manufacturing | Mature (TSMC 4/5nm) | Custom | Wafer-scale | Custom | TSMC 6nm |
| Availability | Purchase or cloud | Cloud API | Cloud API/managed | Enterprise managed | Beta API |
| On-premise | Yes | No (currently) | Limited | Yes (enterprise) | Not yet |
Performance Visualization
The throughput differences are dramatic when visualized:
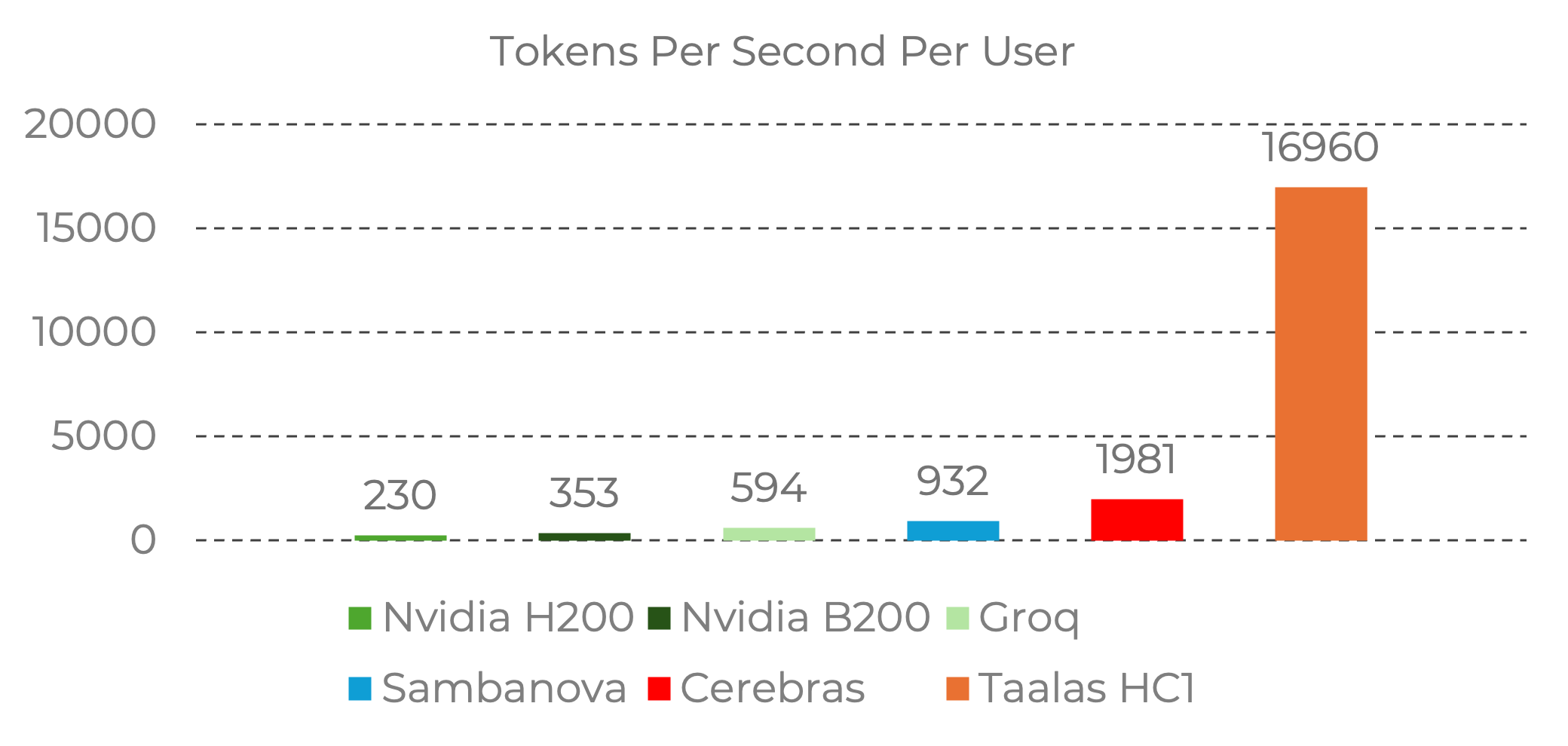 Source: Taalas. Benchmark data from Nvidia official baselines and Artificial Analysis provider data. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
Source: Taalas. Benchmark data from Nvidia official baselines and Artificial Analysis provider data. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
The HC1's 17,000 tokens/sec per user is roughly:
- ~74x faster than Nvidia H200
- ~28x faster than Groq LPU
- ~8.5x faster than Cerebras
These are per-user numbers — measuring how fast a single user gets responses. Total system throughput (all users combined) tells a different story, as GPU systems can serve many users in parallel.
The Fine-Tuning Dimension
Here's where the comparison gets interesting for builders:
Nvidia: Full Fine-Tuning Support
The same GPU that runs inference can also fine-tune models. Full fine-tuning, LoRA, QLoRA — all supported through mature software libraries. This is the most flexible option, but also the most expensive hardware to own.
Groq, Cerebras, SambaNova: No Built-In Fine-Tuning
These inference-optimized platforms run models but don't fine-tune them. You fine-tune elsewhere (on GPUs or a platform like Ertas) and deploy the resulting model to these systems.
This works for full model deployment but doesn't support the adapter-swapping workflow that makes multi-tenant deployments efficient.
Taalas: Hardware-Level LoRA Only
The HC1 takes a unique position: the base model can't be changed (it's in the silicon), but LoRA adapters can be loaded and swapped. This means:
- You fine-tune LoRA adapters elsewhere (GPU, cloud platform)
- You deploy adapters to the HC1 for inference
- You can serve multiple clients by swapping adapters on shared hardware
- You get 17,000 tokens/sec on your fine-tuned model, not just the base
For teams that have validated their use case on Llama 3.1 8B and want maximum inference throughput, this is the optimal path. For teams that need model flexibility, it's too constrained.
Which Hardware Fits Which Use Case?
Use Nvidia GPUs When:
- You need maximum model flexibility (switch between models, run different architectures)
- You want training and inference on the same hardware
- You're running models larger than 8B parameters
- You need mature tooling and a large support ecosystem
- You want on-premise hardware you own
Use Groq When:
- You need fast inference through a cloud API
- Deterministic latency matters (real-time applications)
- You're running supported model architectures
- You don't need on-premise deployment
- You want simple API integration without managing hardware
Use Cerebras When:
- You need very large model inference (70B+)
- Speed matters and you're willing to pay for managed service
- You're working with research or enterprise budgets
- You need both training and inference capability
Use Taalas HC1 When:
- You've validated your use case on Llama 3.1 8B (or a LoRA adapter on it)
- You need the fastest possible per-user throughput
- Cost per token is a primary concern
- You can work within the single-base-model constraint
- You want LoRA adapter flexibility on purpose-built hardware
Use Self-Hosted Consumer GPU When:
- You want the best value for moderate throughput
- You're running fine-tuned models under 14B parameters
- Privacy requires on-premise deployment
- You have basic infrastructure skills
- You want full control at minimal ongoing cost
The Bigger Picture: Inference Hardware Is Specializing
The days of "just use an Nvidia GPU for everything" are ending. The inference market is splitting into niches, each served by purpose-built hardware:
- General-purpose (Nvidia): for R&D, prototyping, and multi-model workloads
- Speed-optimized cloud (Groq, Cerebras): for real-time API-driven inference
- Domain-specific silicon (Taalas): for high-throughput production inference on specific models
This specialization is good news for anyone building fine-tuned models. It means more deployment targets, more competition driving down costs, and more hardware options optimized for the specific workload profile of domain-specific AI.
The constant across all these hardware platforms? You need a fine-tuned model. Whether you deploy on Nvidia, Groq, or Taalas, the model that makes the hardware useful is the one trained on your domain data.
Getting Your Model Ready
The hardware landscape is moving fast. New chips, new architectures, and new pricing models arrive quarterly. The right strategy isn't to pick one hardware platform and bet everything on it. The right strategy is:
-
Fine-tune your model now. Use a platform like Ertas to train a LoRA adapter on your domain data. No hardware dependency, no ML expertise required.
-
Export in portable formats. GGUF for Ollama/llama.cpp. Standard LoRA adapter format for any platform that supports it.
-
Deploy on today's best option. Start with self-hosted GPU or cloud API — whatever fits your current scale.
-
Re-deploy as hardware improves. When Taalas goes GA, or when the next Groq chip ships, your model is ready. Move your adapter, not your entire pipeline.
The fine-tuned model is the permanent asset. The hardware is the replaceable substrate.
Performance data from Taalas, Kaitchup analysis, Nvidia official specifications, and Artificial Analysis provider benchmarks. Pricing reflects publicly available rates as of February 2026.
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading
Ertas vs HuggingFace AutoTrain: Visual Fine-Tuning Without the YAML Configs
Comparing Ertas and HuggingFace AutoTrain for no-code LLM fine-tuning. Covers workflow UX, GGUF export, local deployment, pricing, and dataset format differences.
Ertas vs Modal Labs: Which Is Better for Agencies Fine-Tuning Client Models?
Comparing Ertas and Modal Labs for AI agency fine-tuning workflows. Covers the GUI vs code divide, multi-client management, cost predictability, and GGUF deployment.
Ertas vs Replicate for Fine-Tuning: Cost, Workflow, and GGUF Export Compared
Side-by-side comparison of Ertas and Replicate for fine-tuning language models. Covers workflow, pricing, GGUF export, data privacy, and when to choose each platform.