Taalas HC1: What a Hardwired Llama Chip Means for Fine-Tuning
A Canadian startup just burned Llama 3.1 8B into silicon, achieving 17,000 tokens/sec at $0.0075 per million tokens — up to 74x faster than Nvidia's H200. Here's why the HC1's LoRA support signals that fine-tuning is becoming a hardware-level capability.
A Canadian startup called Taalas just did something that sounds impossible: they took Meta's Llama 3.1 8B model and hardwired it directly into a chip. Not loaded it onto a GPU. Not ran it through a software runtime. They etched the model weights into 53 billion transistors on an 815mm² die.
The result? 17,000 tokens per second per user. That's roughly 8–74x faster than anything else on the market, including Nvidia's H200, Groq's LPU, and Cerebras's wafer-scale engine.
But the speed isn't the most interesting part. The most interesting part is that despite being hardwired, the HC1 supports LoRA fine-tuning. And that changes everything about how we should think about fine-tuning's role in the AI stack.
What Taalas Actually Built
The HC1 is an application-specific integrated circuit (ASIC) manufactured on TSMC's 6nm process. Instead of using general-purpose compute to run model weights from memory — the way every GPU does it — Taalas compiled the Llama 3.1 8B architecture directly into silicon.
The key specs:
| Specification | HC1 |
|---|---|
| Model | Llama 3.1 8B (hardwired) |
| Process | TSMC 6nm |
| Die size | 815mm² |
| Transistors | 53 billion |
| Throughput | ~17,000 tokens/sec per user |
| Power | 2.5 kW server |
| Quantization | Custom 3-bit base + 6-bit parameters |
| LoRA support | Yes (configurable adapters) |
| Context window | Configurable |
The company emerged from stealth mode in February 2026 after raising $169 million (bringing their total to $219 million). They've spent about $30 million of that with a 24-person team — and they built working silicon.
 Source: Taalas. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
Source: Taalas. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
The Performance Gap Is Staggering
The benchmark numbers put the HC1 in a different category from existing inference hardware:
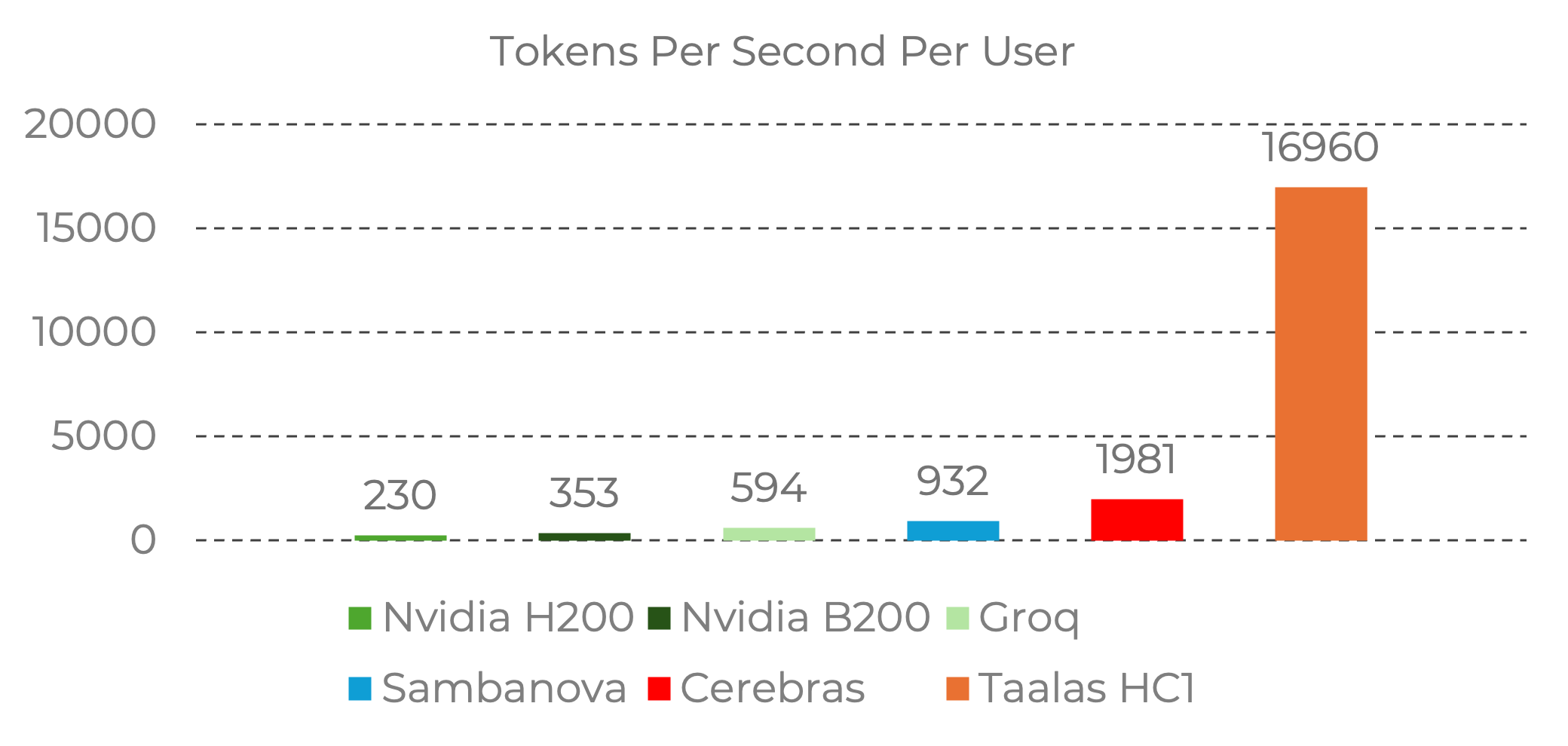 Source: Taalas. Benchmark data from Nvidia official baselines and Artificial Analysis provider data. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
Source: Taalas. Benchmark data from Nvidia official baselines and Artificial Analysis provider data. Image reproduced for editorial commentary. All rights belong to Taalas Inc.
To put these numbers in context:
- Nvidia H200: ~230 tokens/sec per user
- Groq LPU: ~600 tokens/sec per user
- Cerebras: ~2,000 tokens/sec per user
- Taalas HC1: ~17,000 tokens/sec per user
The cost story is equally dramatic. According to analysis by Benjamin Marie at Kaitchup, the HC1 delivers inference at roughly $0.0075 per million tokens — compared to $0.10/M for Cerebras and $2–$15/M for cloud APIs like OpenAI and Anthropic. That's 13x cheaper than the next-cheapest hardware option and up to 2,000x cheaper than cloud APIs.
The trade-off? Flexibility. The HC1 can only run Llama 3.1 8B. You can't load a different model onto it. It's a one-model chip.
But that's where LoRA comes in.
Why LoRA Support on Hardwired Silicon Matters
Here's the detail that should make every builder pay attention: despite the base model being physically baked into transistors, the HC1 supports Low-Rank Adaptation (LoRA) fine-tuning.
LoRA adapters are lightweight customization layers — typically 50–200MB — that sit on top of a base model and specialize it for a specific domain or task. On the HC1, the base Llama 3.1 8B weights are hardwired for speed, while LoRA adapter weights are loaded into on-chip SRAM for flexibility.
This means:
- One chip, many specializations. Load a legal LoRA adapter and the chip runs a legal AI. Swap in a medical LoRA and it runs a clinical AI. The base model never changes; the specialization layer does.
- Hardware-speed fine-tuned inference. Your domain-specific fine-tuned model runs at 17,000 tokens/sec, not just the generic base model.
- The multi-tenant model works in silicon. Agencies running per-client LoRA adapters on shared base infrastructure? That's exactly what the HC1 enables, but at the hardware level.
This is a paradigm shift. LoRA was originally designed as a memory-efficient training technique — a way to fine-tune large models without the cost of full fine-tuning. Now it's becoming a hardware deployment interface. The adapter format isn't just how you train; it's how you deploy on dedicated silicon.
The Economics of Hardwired Fine-Tuned Models
Let's do the math for a real scenario.
An AI agency running 15 client chatbots, each with a different LoRA adapter:
| Deployment | Monthly cost | Tokens/sec | Privacy |
|---|---|---|---|
| OpenAI GPT-4o (15 clients) | $4,200+ | 50–100 | Data sent to OpenAI |
| Self-hosted 8B on GPU | $150–400 | 20–50 | Full control |
| Taalas HC1 + 15 LoRA adapters | Dramatically lower | 17,000 | Full control |
The HC1 isn't available for on-premise purchase yet — Taalas currently offers inference as a beta API service at chatjimmy.ai. But the direction is clear: dedicated hardware for fine-tuned models is moving from theory to production.
The Historical Parallel: CPUs, Smartphones, and AI Chips
This has happened before. Multiple times.
In 1946, ENIAC filled a room and performed 5,000 operations per second. By 1971, Intel's 4004 microprocessor put comparable compute on a chip the size of a fingernail. By 2007, the iPhone put a full computer in everyone's pocket.
Each hardware generation didn't just make existing tasks faster — it created entirely new categories of use. Mainframes served enterprises. PCs served knowledge workers. Smartphones served everyone.
AI inference is on the same trajectory:
- Data center GPUs (2020–2024): AI as a cloud service
- Edge inference (2024–2026): AI on local hardware (Ollama, llama.cpp, LM Studio)
- Dedicated silicon (2026+): AI hardwired into purpose-built chips
- On-device (next): AI embedded in every device
The HC1 sits at stage 3. And just like the microprocessor needed software (operating systems, applications) to become useful beyond raw compute, dedicated AI silicon needs fine-tuned models to become useful beyond running a generic chatbot.
Fine-tuning is the software layer that makes dedicated AI hardware valuable.
What's Coming Next from Taalas
Taalas has outlined a clear roadmap:
- Spring 2026: Mid-sized reasoning model on HC1 platform — bringing chain-of-thought and multi-step reasoning to dedicated silicon
- Winter 2026: Frontier LLM on HC2 platform — a second-generation chip with higher density and faster execution
- Future generations: The second-generation silicon will use standard 4-bit floating-point formats, addressing the quality compromises from HC1's aggressive 3-bit quantization
The company claims they can convert a new model into working silicon in approximately two months. If that holds, every major open-weight model release becomes a potential HC-series chip.
What This Means for Builders Right Now
You don't need to wait for Taalas to ship hardware to your door to act on this signal.
The takeaway is strategic: Hardware vendors are building LoRA support into their silicon because they see fine-tuning as the deployment interface of the future. If you're building AI into your product, your workflow, or your agency's offerings, the model you deploy should be fine-tuned for your domain.
Here's what to do now:
-
Fine-tune on open-weight models today. Llama, Qwen, Gemma, Phi — pick the base model that fits your task. The fine-tuned LoRA adapter you create today will work on GPUs now and on dedicated silicon later.
-
Export as portable formats. GGUF for local inference (Ollama, llama.cpp, LM Studio). LoRA adapters in standard formats. Don't lock yourself into one deployment target.
-
Think in adapters, not monolithic models. One base model + multiple LoRA adapters = one training investment that serves many clients, many use cases, many deployment targets.
-
Start with the use case, not the hardware. Whether you deploy on a GPU, an edge device, or dedicated silicon, the fine-tuned model is the constant. The hardware is the variable.
The Fine-Tuning Window Is Open
Taalas is one signal in a broader trend. Edge AI hardware is projected to reach $59 billion by 2030. Inference workloads are expected to account for two-thirds of all AI compute by the end of 2026. And the models that will run on all this hardware need to be fine-tuned for specific domains to be useful.
The teams that learn to fine-tune now — that build the datasets, train the adapters, and validate the quality — will have production-ready models when the hardware catches up. Those who wait will be starting from scratch while their competitors are already deployed.
Ertas makes fine-tuning accessible to builders who don't have ML expertise. Upload a dataset, fine-tune visually, export as GGUF or LoRA adapter, deploy anywhere. The model you fine-tune today is the model that runs on tomorrow's hardware.
This article references information from Taalas's announcement and product page, with additional analysis from WCCFTech, EE Times, Data Center Dynamics, and Kaitchup.
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading
Why Hardware Companies Are Building LoRA Support Into Their Chips
Taalas, Apple, Qualcomm, and others are adding LoRA adapter support to their AI silicon. It's not a coincidence — LoRA is becoming the standard interface between fine-tuned models and inference hardware.
LoRA on Silicon: How Hardware Is Making Fine-Tuning a First-Class Citizen
From Taalas's HC1 to Tether Data's QVAC Fabric LLM, hardware vendors are building LoRA support directly into their platforms. Fine-tuning is no longer just a training technique — it's becoming a hardware deployment interface.
Taalas vs Nvidia vs Groq vs Cerebras: AI Inference Hardware Compared (2026)
A detailed comparison of AI inference hardware in 2026: Taalas HC1 (model-on-silicon), Nvidia H200/B200 (general GPU), Groq LPU, Cerebras wafer-scale, and SambaNova. Performance, cost, flexibility, and fine-tuning support compared.