Taalas vs Nvidia vs Groq vs Cerebras: Hardware de Inferencia AI Comparado (2026)
Una comparación detallada del hardware de inferencia AI en 2026: Taalas HC1 (modelo en silicio), Nvidia H200/B200 (GPU general), Groq LPU, Cerebras a escala de wafer y SambaNova. Rendimiento, costo, flexibilidad y soporte de fine-tuning comparados.
El mercado de hardware de inferencia AI se está fragmentando. Durante años, las GPUs de Nvidia eran la única opción seria para ejecutar modelos de lenguaje grandes. En 2026, al menos cinco enfoques fundamentalmente diferentes compiten por cargas de trabajo de inferencia — cada uno con diferentes compromisos entre velocidad, costo, flexibilidad y soporte de fine-tuning.
Esta comparación desglosa lo que ofrece cada enfoque y dónde encaja.
Los Contendientes
Nvidia: GPU de Propósito General
Enfoque: GPUs de propósito general con paralelismo masivo y gran HBM (High Bandwidth Memory). El mismo hardware entrena y sirve modelos.
Productos actuales: H100 (80GB HBM3), H200 (141GB HBM3e), B200 (192GB HBM3e)
Fortalezas clave:
- Ejecuta cualquier arquitectura de modelo, cualquier tamaño
- Fine-tuning completo e inferencia en el mismo hardware
- Mayor ecosistema de software (CUDA, TensorRT, vLLM)
- Probado a escala en todas las principales empresas de AI
Limitaciones clave:
- Costoso ($25,000-$40,000+ por GPU)
- Alto consumo de energía (700W+ por GPU)
- El throughput por usuario es modesto en relación al hardware especializado
- Oferta limitada en el extremo alto
Rendimiento de inferencia (Llama 3.1 8B): ~230 tokens/seg por usuario en H200
Groq: Language Processing Unit (LPU)
Enfoque: Chips de inferencia diseñados a medida llamados Language Processing Units (LPUs). Optimizados para generación secuencial de tokens con ejecución determinista — sin overhead de programación variable.
Fortalezas clave:
- Inferencia muy rápida por usuario (~600 tokens/seg en clase Llama 8B)
- Latencia determinista (sin tiempos de espera variables)
- Diseñado específicamente para inferencia autoregresiva
- Disponible como API en la nube
Limitaciones clave:
- Solo inferencia — sin capacidad de entrenamiento
- Limitado a arquitecturas de modelo soportadas
- Sin soporte de fine-tuning a nivel de hardware
- Actualmente solo disponible como servicio en la nube
Cerebras: Motor a Escala de Wafer
Enfoque: Un wafer de silicio completo como un solo chip. El CS-3 contiene 4 billones de transistores y 900,000 núcleos en un solo wafer. Diseñado para entrenamiento e inferencia a escala extrema.
Fortalezas clave:
- Memoria on-chip masiva que elimina el cuello de botella de memoria
- Inferencia rápida (~2,000 tokens/seg por usuario en clase Llama 8B)
- Puede manejar modelos muy grandes en un solo sistema
- Disponible como API de inferencia en la nube
Limitaciones clave:
- Hardware extremadamente costoso
- Principalmente disponible como servicio gestionado
- La fabricación a escala de wafer tiene rendimientos más bajos
- Sin soporte incorporado de LoRA/fine-tuning a nivel de hardware
SambaNova: Arquitectura de Flujo de Datos Reconfigurable
Enfoque: Unidades de Flujo de Datos Reconfigurables (RDUs) que pueden optimizarse para diferentes arquitecturas de modelo. Diseñadas para manejar tanto entrenamiento como inferencia.
Fortalezas clave:
- Reconfigurable para diferentes arquitecturas de modelo
- Maneja entrenamiento e inferencia
- Enfocado en empresas con ofertas de servicio gestionado
- Soporta múltiples tamaños de modelo
Limitaciones clave:
- Ecosistema más pequeño que Nvidia
- Datos de benchmark públicos limitados comparados con competidores
- Principalmente despliegue empresarial/nube
Taalas: Modelo en Silicio (ASIC)
Enfoque: Grabar los pesos de un modelo específico directamente en los transistores de un ASIC. En lugar de cargar pesos desde memoria, el modelo es el chip. El HC1 es su primer producto, ejecutando Llama 3.1 8B.
Fortalezas clave:
- Inferencia más rápida por usuario: ~17,000 tokens/seg
- Menor costo por token: ~$0.0075/M tokens
- Menor consumo de energía: servidor de 2.5 kW
- Soporte de adaptadores LoRA para personalización
- 20x menor costo de construcción que alternativas GPU
Limitaciones clave:
- Bloqueado a un solo modelo base (Llama 3.1 8B en HC1)
- Cuantización agresiva (3 bits) introduce compromisos de calidad
- Producto en beta — aún no disponible para compra on-premise
- No puede ejecutar diferentes arquitecturas de modelo
Comparación Directa
| Nvidia H200 | Groq LPU | Cerebras CS-3 | SambaNova | Taalas HC1 | |
|---|---|---|---|---|---|
| Arquitectura | GPU General | LPU Personalizado | Escala de Wafer | Flujo de Datos RDU | ASIC Modelo en Silicio |
| Tokens/seg/usuario (8B) | ~230 | ~600 | ~2,000 | ~800 (est.) | ~17,000 |
| Costo por 1M tokens | ~$0.50-2.00 | ~$0.05-0.27 | ~$0.10 | N/A (empresarial) | ~$0.0075 |
| Flexibilidad de modelo | Cualquier modelo | Múltiples | Múltiples | Múltiples | Único + LoRA |
| Soporte de entrenamiento | Completo | Ninguno | Completo | Completo | Ninguno (solo inferencia LoRA) |
| Fine-tuning LoRA | Completo | No | No | No | LoRA a nivel de hardware |
| Potencia por unidad | 700W+ | ~300W | Alto | Medio | ~250W por tarjeta |
| Fabricación | Madura (TSMC 4/5nm) | Personalizada | Escala de Wafer | Personalizada | TSMC 6nm |
| Disponibilidad | Compra o nube | API en la nube | API en la nube/gestionado | Gestionado empresarial | API en beta |
| On-premise | Sí | No (actualmente) | Limitado | Sí (empresarial) | Aún no |
Visualización de Rendimiento
Las diferencias de throughput son dramáticas cuando se visualizan:
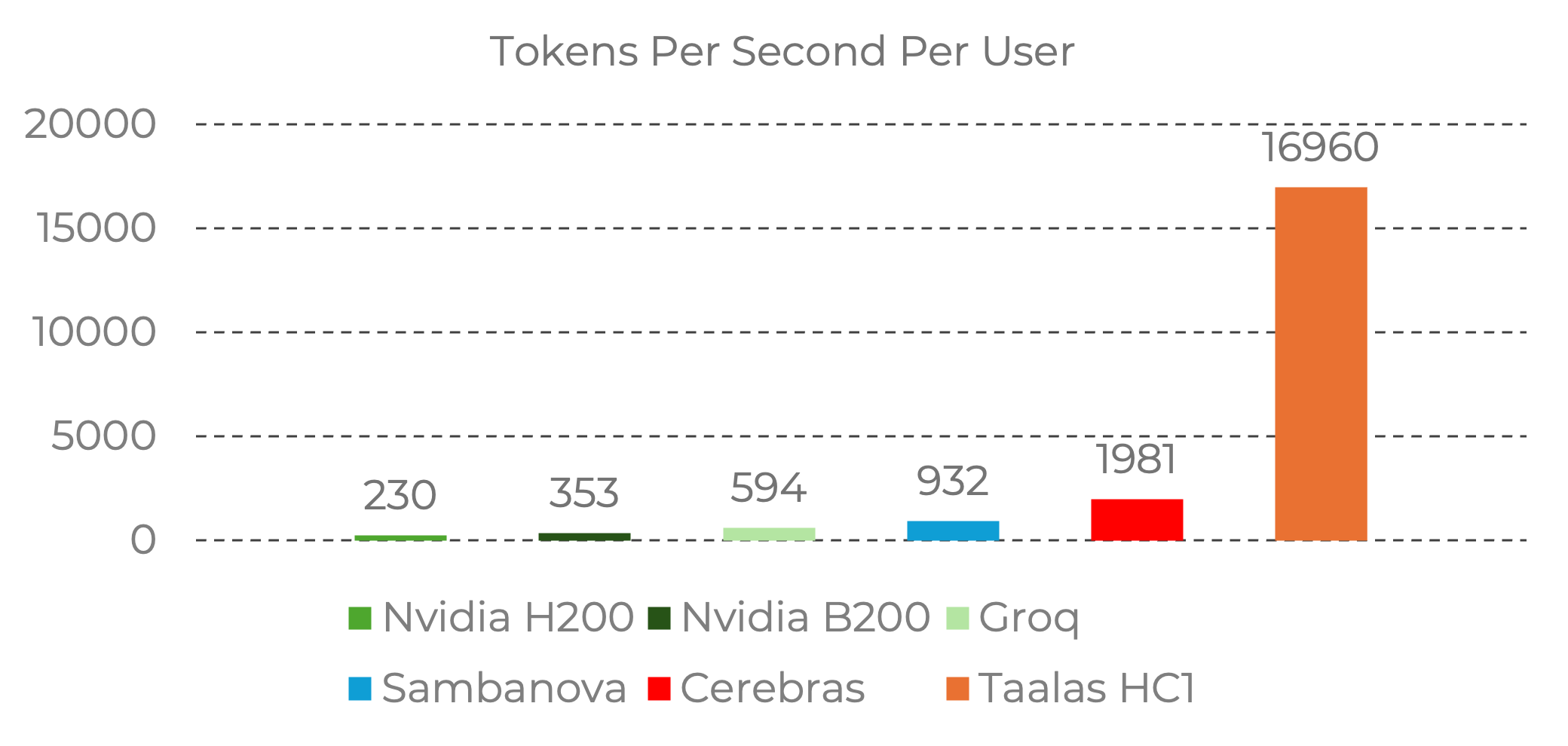 Fuente: Taalas. Datos de benchmark de las líneas base oficiales de Nvidia y datos de proveedores de Artificial Analysis. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
Fuente: Taalas. Datos de benchmark de las líneas base oficiales de Nvidia y datos de proveedores de Artificial Analysis. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
Los 17,000 tokens/seg por usuario del HC1 son aproximadamente:
- ~74x más rápido que Nvidia H200
- ~28x más rápido que Groq LPU
- ~8.5x más rápido que Cerebras
Estos son números por usuario — midiendo qué tan rápido un solo usuario obtiene respuestas. El throughput total del sistema (todos los usuarios combinados) cuenta una historia diferente, ya que los sistemas GPU pueden servir a muchos usuarios en paralelo.
La Dimensión del Fine-Tuning
Aquí es donde la comparación se pone interesante para los constructores:
Nvidia: Soporte Completo de Fine-Tuning
La misma GPU que ejecuta inferencia también puede ajustar modelos. Fine-tuning completo, LoRA, QLoRA — todos soportados a través de bibliotecas de software maduras. Esta es la opción más flexible, pero también el hardware más costoso de poseer.
Groq, Cerebras, SambaNova: Sin Fine-Tuning Incorporado
Estas plataformas optimizadas para inferencia ejecutan modelos pero no los ajustan. Ajustas en otro lugar (en GPUs o una plataforma como Ertas) y despliegas el modelo resultante en estos sistemas.
Esto funciona para despliegue de modelo completo pero no soporta el flujo de trabajo de intercambio de adaptadores que hace eficientes los despliegues multi-tenant.
Taalas: Solo LoRA a Nivel de Hardware
El HC1 toma una posición única: el modelo base no puede cambiarse (está en el silicio), pero los adaptadores LoRA pueden cargarse e intercambiarse. Esto significa:
- Ajustas adaptadores LoRA en otro lugar (GPU, plataforma en la nube)
- Despliegas adaptadores en el HC1 para inferencia
- Puedes servir a múltiples clientes intercambiando adaptadores en hardware compartido
- Obtienes 17,000 tokens/seg en tu modelo ajustado, no solo en el base
Para equipos que han validado su caso de uso en Llama 3.1 8B y quieren máximo throughput de inferencia, este es el camino óptimo. Para equipos que necesitan flexibilidad de modelo, es demasiado restrictivo.
¿Qué Hardware Se Ajusta a Qué Caso de Uso?
Usa GPUs Nvidia Cuando:
- Necesitas máxima flexibilidad de modelo (cambiar entre modelos, ejecutar diferentes arquitecturas)
- Quieres entrenamiento e inferencia en el mismo hardware
- Estás ejecutando modelos mayores a 8B parámetros
- Necesitas herramientas maduras y un ecosistema de soporte grande
- Quieres hardware on-premise de tu propiedad
Usa Groq Cuando:
- Necesitas inferencia rápida a través de una API en la nube
- La latencia determinista importa (aplicaciones en tiempo real)
- Estás ejecutando arquitecturas de modelo soportadas
- No necesitas despliegue on-premise
- Quieres integración simple de API sin gestionar hardware
Usa Cerebras Cuando:
- Necesitas inferencia de modelos muy grandes (70B+)
- La velocidad importa y estás dispuesto a pagar por servicio gestionado
- Trabajas con presupuestos de investigación o empresariales
- Necesitas capacidad tanto de entrenamiento como de inferencia
Usa Taalas HC1 Cuando:
- Has validado tu caso de uso en Llama 3.1 8B (o un adaptador LoRA sobre él)
- Necesitas el throughput por usuario más rápido posible
- El costo por token es una preocupación primaria
- Puedes trabajar dentro de la restricción de modelo base único
- Quieres flexibilidad de adaptadores LoRA en hardware diseñado específicamente
Usa GPU de Consumo Auto-Hospedada Cuando:
- Quieres la mejor relación calidad-precio para throughput moderado
- Estás ejecutando modelos ajustados de menos de 14B parámetros
- La privacidad requiere despliegue on-premise
- Tienes habilidades básicas de infraestructura
- Quieres control total al mínimo costo continuo
El Panorama General: El Hardware de Inferencia Se Está Especializando
Los días de "simplemente usa una GPU de Nvidia para todo" están terminando. El mercado de inferencia se está dividiendo en nichos, cada uno servido por hardware diseñado específicamente:
- Propósito general (Nvidia): para I+D, prototipado y cargas de trabajo multi-modelo
- Nube optimizada para velocidad (Groq, Cerebras): para inferencia en tiempo real impulsada por API
- Silicio específico de dominio (Taalas): para inferencia de producción de alto throughput en modelos específicos
Esta especialización es buena noticia para cualquiera que construya modelos ajustados. Significa más objetivos de despliegue, más competencia reduciendo costos y más opciones de hardware optimizadas para el perfil de carga de trabajo específico de AI de dominio específico.
¿La constante en todas estas plataformas de hardware? Necesitas un modelo ajustado. Ya sea que despliegues en Nvidia, Groq o Taalas, el modelo que hace útil al hardware es el entrenado en los datos de tu dominio.
Preparando Tu Modelo
El panorama de hardware se mueve rápido. Nuevos chips, nuevas arquitecturas y nuevos modelos de precios llegan trimestralmente. La estrategia correcta no es elegir una plataforma de hardware y apostar todo a ella. La estrategia correcta es:
-
Ajusta tu modelo ahora. Usa una plataforma como Ertas para entrenar un adaptador LoRA con los datos de tu dominio. Sin dependencia de hardware, sin experiencia en ML requerida.
-
Exporta en formatos portables. GGUF para Ollama/llama.cpp. Formato estándar de adaptador LoRA para cualquier plataforma que lo soporte.
-
Despliega en la mejor opción de hoy. Comienza con GPU auto-hospedada o API en la nube — lo que se ajuste a tu escala actual.
-
Re-despliega a medida que el hardware mejora. Cuando Taalas se lance en GA, o cuando el próximo chip de Groq se envíe, tu modelo está listo. Mueve tu adaptador, no todo tu pipeline.
El modelo ajustado es el activo permanente. El hardware es el sustrato reemplazable.
Datos de rendimiento de Taalas, análisis de Kaitchup, especificaciones oficiales de Nvidia y benchmarks de proveedores de Artificial Analysis. Los precios reflejan tarifas disponibles públicamente a febrero de 2026.
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading
Ertas vs HuggingFace AutoTrain: Fine-Tuning Visual Sin las Configuraciones YAML
Comparando Ertas y HuggingFace AutoTrain para fine-tuning de LLM sin código. Cubre UX del flujo de trabajo, exportación GGUF, despliegue local, precios y diferencias de formato de dataset.
Ertas vs Modal Labs: ¿Cuál Es Mejor para Agencias que Ajustan Modelos de Clientes?
Comparando Ertas y Modal Labs para flujos de trabajo de fine-tuning en agencias de IA. Cubre la división GUI vs código, gestión multi-cliente, previsibilidad de costos y despliegue GGUF.
Ertas vs Replicate para Fine-Tuning: Costo, Flujo de Trabajo y Exportación GGUF Comparados
Comparación lado a lado de Ertas y Replicate para ajustar modelos de lenguaje. Cubre flujo de trabajo, precios, exportación GGUF, privacidad de datos y cuándo elegir cada plataforma.