
Taalas vs Nvidia vs Groq vs Cerebras:AI 推論硬體比較(2026 年)
2026 年 AI 推論硬體詳細比較:Taalas HC1(模型燒入矽晶片)、Nvidia H200/B200(通用 GPU)、Groq LPU、Cerebras 晶圓級引擎和 SambaNova。效能、成本、靈活性和微調支援的全面比較。
AI 推論硬體市場正在碎片化。多年來,Nvidia GPU 是運行大型語言模型的唯一嚴肅選擇。2026 年,至少有五種根本不同的方法在爭奪推論工作負載——每種方法在速度、成本、靈活性和微調支援之間有不同的取捨。
本比較文章解析了每種方法的提供內容及其適用場景。
競爭者
Nvidia:通用 GPU
方法: 具有大規模並行性和大容量 HBM(高頻寬記憶體)的通用 GPU。相同的硬體可用於訓練和服務模型。
當前產品: H100(80GB HBM3)、H200(141GB HBM3e)、B200(192GB HBM3e)
主要優勢:
- 可運行任何模型架構、任何規模
- 在相同硬體上進行全量微調和推論
- 最大的軟體生態系(CUDA、TensorRT、vLLM)
- 在每家主要 AI 公司大規模驗證
主要限制:
- 昂貴(每個 GPU 25,000–40,000 美元以上)
- 高功耗(每個 GPU 700W 以上)
- 相對於專用硬體,每位用戶吞吐量適中
- 高端供應受限
推論效能(Llama 3.1 8B): H200 約 230 token/秒/用戶
Groq:語言處理單元(LPU)
方法: 稱為語言處理單元(LPU)的自訂推論晶片。針對具有確定性執行的循序 token 生成進行優化——無可變排程開銷。
主要優勢:
- 每位用戶推論非常快速(Llama 8B 級別約 600 token/秒)
- 確定性延遲(無可變等待時間)
- 專為自��回歸推論設計
- 可作為雲端 API 使用
主要限制:
- 僅推論——無訓練能力
- 限於支援的模型架構
- 無硬體層面的微調支援
- 目前僅作為雲端服務提供
Cerebras:晶圓級引擎
方法: 整個矽晶圓作為單一晶片。CS-3 在單個晶圓上包含 4 兆個電晶體和 90 萬個核心。設計用於極端規模的訓練和推論。
主要優勢:
- 大量片上記憶體消除記憶體瓶頸
- 快速推論(Llama 8B 級別約 2,000 token/秒/用戶)
- 可在單個系統上處理非常大的模型
- 可作為雲端推論 API 使用
主要限制:
- 硬體極其昂貴
- 主要作為託管服務提供
- 晶圓級製造良率較低
- 在硬體層面無內建 LoRA/微調支援
SambaNova:可重配置資料流架構
方法: 可針對不同模型架構優化的可重配置資料流單元(RDU)。設計用於處理訓練和推論。
主要優勢:
- 可針對不同模型架構重新配置
- 處理訓練和推論
- 以企業為重點,提供託管服務
- 支援多種模型規模
主要限制:
- 生態系比 Nvidia 小
- 與競爭對手相比,公開基準數據有限
- 主要面向企業/雲端部署
Taalas:模型燒入矽晶片(ASIC)
方法: 將特定模型的權重直接硬連線進 ASIC 的電晶體中。模型即晶片,而非從記憶體載入權重。HC1 是他們的第一款產品,運行 Llama 3.1 8B。
主要優勢:
- 最快的每位用戶推論:約 17,000 token/秒
- 最低的每 token 成本:約 0.0075 美元/百萬 token
- 最低功耗:2.5kW 伺服器
- 支援 LoRA adapter 進行定制
- 建設成本比 GPU 替代方案低 20 倍
主要限制:
- 鎖定在單一基礎模型(HC1 上的 Llama 3.1 8B)
- 激進的量化(3-bit)引入品質取捨
- 測試版產品——尚不可本地採購
- 無法運行不同的模型架構
正面比較
| Nvidia H200 | Groq LPU | Cerebras CS-3 | SambaNova | Taalas HC1 | |
|---|---|---|---|---|---|
| 架構 | 通用 GPU | 自訂 LPU | 晶圓級 | 資料流 RDU | 模型燒入矽晶片 ASIC |
| Token/秒/用戶(8B) | 約 230 | 約 600 | 約 2,000 | 約 800(估計) | 約 17,000 |
| 每百萬 token 成本 | 約 0.50–2.00 美元 | 約 0.05–0.27 美元 | 約 0.10 美元 | 不適用(企業) | 約 0.0075 美元 |
| 模型靈活性 | 任何模型 | 多種 | 多種 | 多種 | 單一 + LoRA |
| 訓練支援 | 完整 | 無 | 完整 | 完整 | 無(僅 LoRA 推論) |
| LoRA 微調 | 完整 | 否 | 否 | 否 | 硬體層面 LoRA |
| 每單元功耗 | 700W 以上 | 約 300W | 高 | 中等 | 每張卡約 250W |
| 製造 | 成熟(台積電 4/5nm) | 自訂 | 晶圓級 | 自訂 | 台積電 6nm |
| 供應方式 | 購買或雲端 | 雲端 API | 雲端 API/託管 | 企業託管 | 測試版 API |
| 本地部署 | 是 | 否(目前) | 有限 | 是(企業) | 尚未 |
效能視覺化
吞吐量差異以視覺化方式呈現時非常顯著:
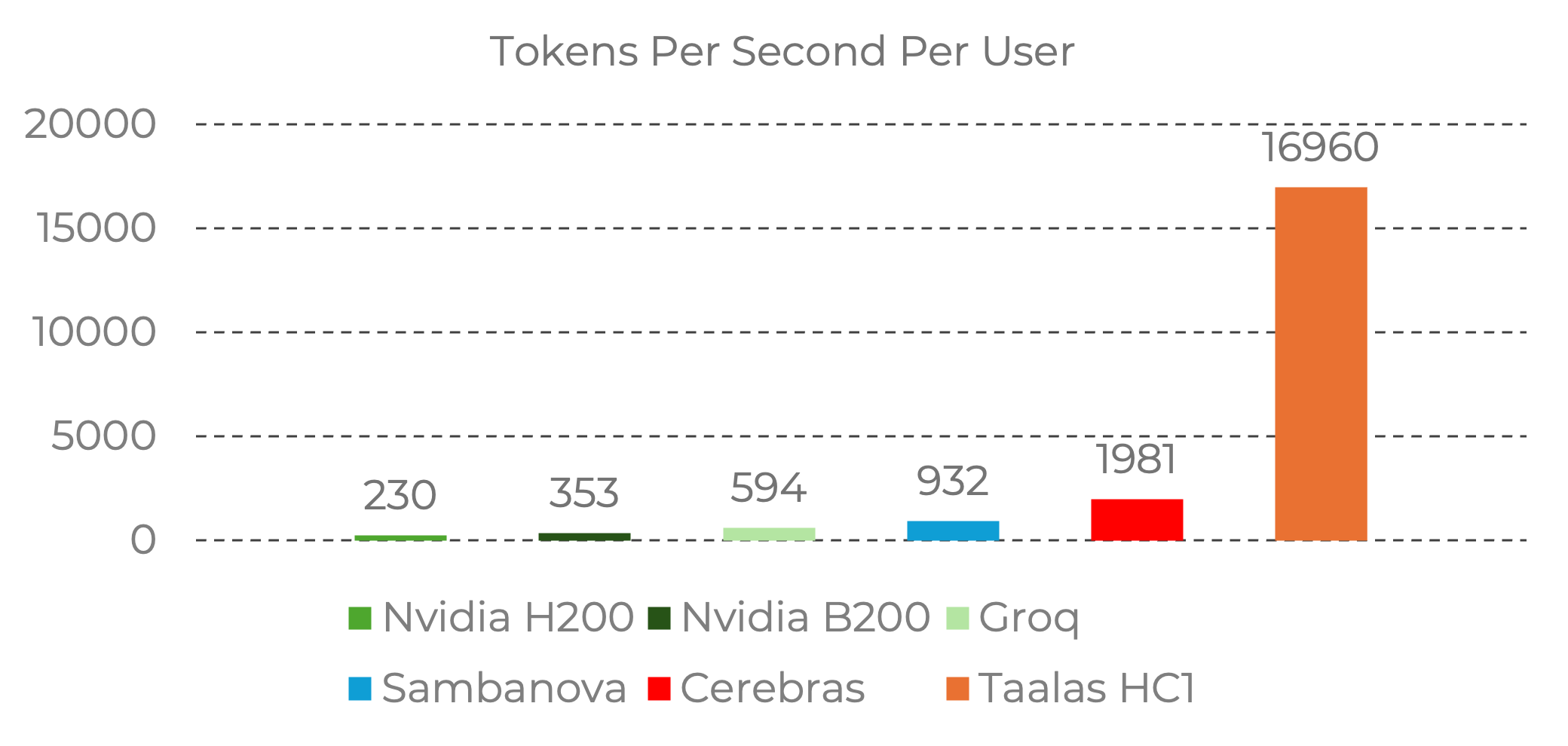 來源:Taalas。基準數據來自 Nvidia 官方基準和 Artificial Analysis 服務商數據。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
來源:Taalas。基準數據來自 Nvidia 官方基準和 Artificial Analysis 服務商數據。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
HC1 的每位用戶 17,000 token/秒大約是:
- 比 Nvidia H200 快約 74 倍
- 比 Groq LPU 快約 28 倍
- 比 Cerebras 快約 8.5 倍
這些是每用戶數字——衡量單個用戶獲得回應的速度。總系統吞吐量(所有用戶合計)呈現不同的面貌,因為 GPU 系統可以並行服務許多用戶。
微調維度
這是比較對開發者變得有趣的地方:
Nvidia:完整微調支援
運行推論的 GPU 同樣可以微調模型。完整微調、LoRA、QLoRA——通過成熟的軟體庫全部支援。這是最靈活的選項,但也是擁有成本最高的硬體。
Groq、Cerebras、SambaNova:無內建微調
這些推論優化平台可以運行模型但不能微調它們。您在別處微調(在 GPU 上或 Ertas 等平台上),然後將生成的模型部署到這些系統。
這適用於完整模型部署,但不支援使多租戶部署高效的 adapter 交換工作流程。
Taalas:僅硬體層面 LoRA
HC1 佔據了獨特的位置:基礎模型無法更改(它在矽晶片中),但 LoRA adapter 可以載入和交換。這意味著:
- 您在別處微調 LoRA adapter(GPU、雲端平台)
- 您將 adapter 部署到 HC1 進行推論
- 您可以透過在共享硬體上交換 adapter 服務多個客戶
- 您以 17,000 token/秒在微調後的模型上運行,而不只是基礎模型
對於已在 Llama 3.1 8B 上驗證其使用場景並需要最大推論吞吐量的團隊,這是最佳路徑。對於需要模型靈活性的團隊,限制太多。
哪種硬體適合哪種使用場景?
使用 Nvidia GPU 的時機:
- 您需要最大的模型靈活性(切換模型,運行不同架構)
- 您希望在相同硬體上進行訓練和推論
- 您運行的模型超過 80 億參數
- 您需要成熟的工具和大型支援生態系
- 您想要本地擁有的硬體
使用 Groq 的時機:
- 您需要透過雲端 API 快速推論
- 確定性延遲很重要(即時應用程式)
- 您運行支援的模型架構
- 您不需要本地部署
- 您希望簡單的 API 整合而無需管理硬體
使用 Cerebras 的時機:
- 您需要非常大型模型推論(700 億以上參數)
- 速度很重要且您願意為託管服務付費
- 您在研究或企�業預算下工作
- 您需要訓練和推論能力
使用 Taalas HC1 的時機:
- 您已在 Llama 3.1 8B(或其 LoRA adapter)上驗證了您的使用場景
- 您需要最快的每位用戶吞吐量
- 每 token 成本是主要考量
- 您可以在單一基礎模型的限制下工作
- 您希望在專用硬體上的 LoRA adapter 靈活性
使用自行託管消費者 GPU 的時機:
- 您希望在適中吞吐量下獲得最佳性價比
- 您運行 140 億參數以下的微調模型
- 隱私要求本地部署
- 您有基本的基礎設施技能
- 您希望以最低持續成本完全控制
更大的圖景:推論硬體正在專業化
「所有事情都只用 Nvidia GPU」的時代正在結束。推論市場正在分裂為利基市場,每個市場由專用硬體服務:
- 通用(Nvidia):用於研發、原型設計和多模型工作負載
- 速度優化雲端(Groq、Cerebras):用於即時 API 驅動的推論
- 領域專屬矽晶片(Taalas):用於特定模型的高吞吐量生產推論
這種專業化對構建微調模型的任何人來說都是好消息。它意味著更多的部署目標、更多推動降低成本的競爭,以及更多針對領域專屬 AI 的特定工作負載配置優化的硬體選項。
在所有這些硬體平台上不變的是什麼?您需要一個微調後的模型。 無論您在 Nvidia、Groq 還是 Taalas 上部署,使硬體有用的模型是那個在您的領域資料上訓練的模型。
讓您的模型準備就緒
硬體格局正在快速變化。每季度都有新晶片、新架構和新定價模型出現。正確的策略不是選擇一個硬體平台並全押。正確的策略是:
-
現在就微調您的模型。 使用 Ertas 等平台在您的領域資料上訓練 LoRA adapter。無硬體依賴,無需 ML 專業知識。
-
以可攜格式匯出。 用於 Ollama/llama.cpp 的 GGUF。標準 LoRA adapter 格式用於任何支援它的平台。
-
在今天最佳的選項上部署。 從自行託管 GPU 或雲端 API 開始——適合您當前規模的任何選擇。
-
隨著硬體改善重新部署。 當 Taalas 正式發布,或下一代 Groq 晶片問世時,您的模型已經準備好了。移動您的 adapter,而非整個管線。
微調後的模型是永久資產。硬體是可替換的基底。
效能數據來自 Taalas、Kaitchup 分析、Nvidia 官方規格和 Artificial Analysis 服務商基準測試。定價反映截至 2026 年 2 月的公開可用費率。
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading

Ertas vs HuggingFace AutoTrain:無需 YAML 配置的視覺化微調
比較 Ertas 和 HuggingFace AutoTrain 的無代碼 LLM 微調。涵蓋工作流程 UX、GGUF 匯出、本地部署、定價和資料集格式差異。

Ertas vs Modal Labs:哪個更適合為客戶微調模型的機構?
比較 Ertas 和 Modal Labs 用於 AI 機構微調工作流程。涵蓋 GUI vs 代碼的分歧、多客戶管理、成本可預測性和 GGUF 部署。

Ertas vs Replicate 微調比較:成本、工作流程和 GGUF 匯出
Ertas 和 Replicate 微調語言模型的並排比較。涵蓋工作流程、定價、GGUF 匯出、資料隱私,以及何時選擇每個平台。