Taalas HC1: Lo Que Significa un Chip Llama Hardwired para Fine-Tuning
Una startup canadiense acaba de grabar Llama 3.1 8B en silicio, logrando 17,000 tokens/seg a $0.0075 por millón de tokens — hasta 74x más rápido que el H200 de Nvidia. Por qué el soporte LoRA del HC1 señala que el fine-tuning se está convirtiendo en una capacidad a nivel de hardware.
Una startup canadiense llamada Taalas acaba de hacer algo que suena imposible: tomaron el modelo Llama 3.1 8B de Meta y lo grabaron directamente en un chip. No lo cargaron en una GPU. No lo ejecutaron a través de un runtime de software. Grabaron los pesos del modelo en 53 mil millones de transistores en un die de 815mm².
¿El resultado? 17,000 tokens por segundo por usuario. Eso es aproximadamente 8-74x más rápido que cualquier otra cosa en el mercado, incluyendo el H200 de Nvidia, el LPU de Groq y el motor a escala de wafer de Cerebras.
Pero la velocidad no es la parte más interesante. La parte más interesante es que a pesar de estar hardwired, el HC1 soporta fine-tuning LoRA. Y eso cambia todo sobre cómo deberíamos pensar sobre el rol del fine-tuning en el stack de AI.
Lo Que Taalas Realmente Construyó
El HC1 es un circuito integrado de aplicación específica (ASIC) fabricado en el proceso de 6nm de TSMC. En lugar de usar cómputo de propósito general para ejecutar pesos del modelo desde memoria — la manera en que cada GPU lo hace — Taalas compiló la arquitectura de Llama 3.1 8B directamente en silicio.
Las especificaciones clave:
| Especificación | HC1 |
|---|---|
| Modelo | Llama 3.1 8B (hardwired) |
| Proceso | TSMC 6nm |
| Tamaño del die | 815mm² |
| Transistores | 53 mil millones |
| Throughput | ~17,000 tokens/seg por usuario |
| Potencia | Servidor de 2.5 kW |
| Cuantización | Base de 3 bits personalizada + parámetros de 6 bits |
| Soporte LoRA | Sí (adaptadores configurables) |
| Ventana de contexto | Configurable |
La empresa salió del modo stealth en febrero de 2026 después de recaudar $169 millones (llevando su total a $219 millones). Han gastado cerca de $30 millones de eso con un equipo de 24 personas — y construyeron silicio funcional.
 Fuente: Taalas. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
Fuente: Taalas. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
La Brecha de Rendimiento Es Asombrosa
Los números de benchmark ponen al HC1 en una categoría diferente del hardware de inferencia existente:
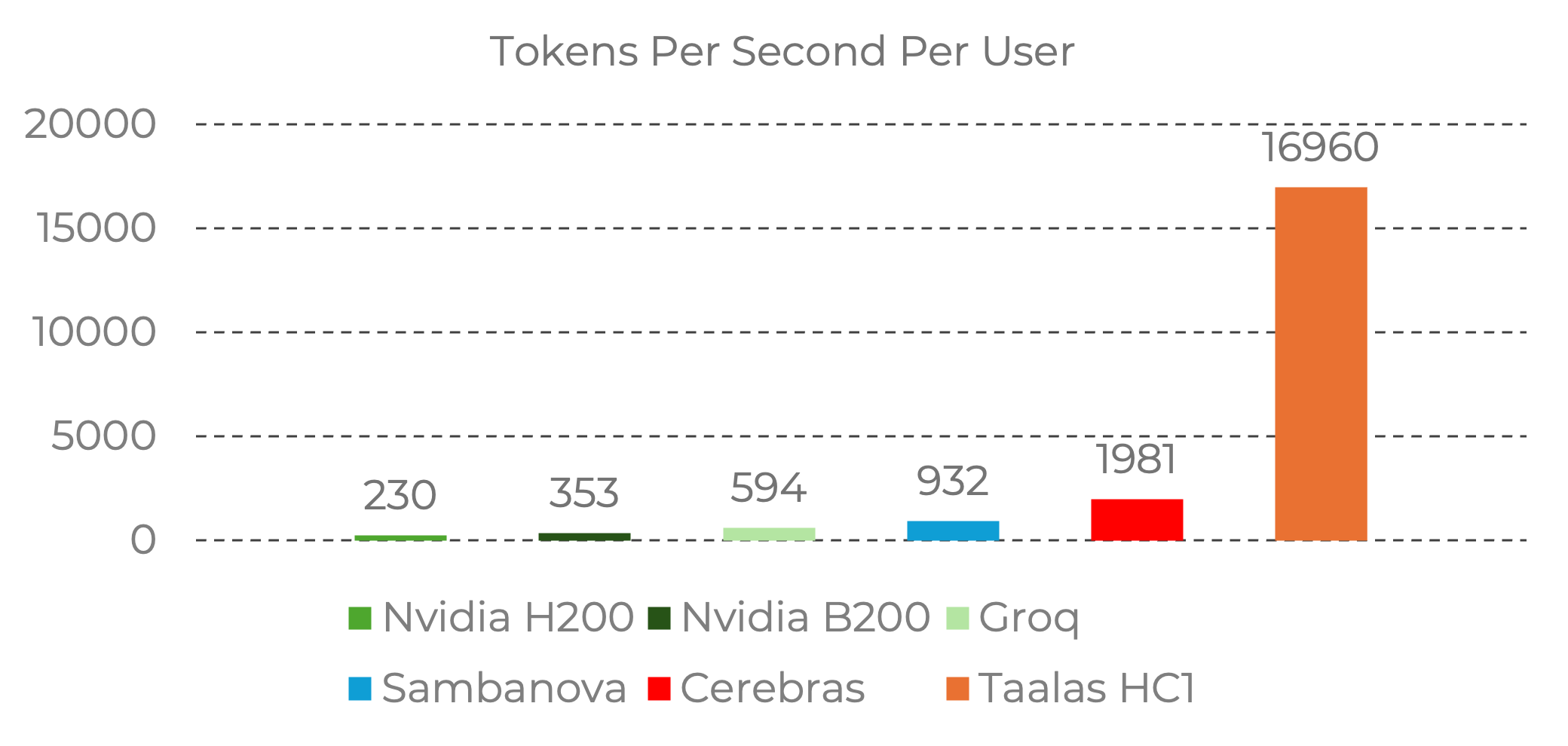 Fuente: Taalas. Datos de benchmark de las líneas base oficiales de Nvidia y datos de proveedores de Artificial Analysis. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
Fuente: Taalas. Datos de benchmark de las líneas base oficiales de Nvidia y datos de proveedores de Artificial Analysis. Imagen reproducida para comentario editorial. Todos los derechos pertenecen a Taalas Inc.
Para poner estos números en contexto:
- Nvidia H200: ~230 tokens/seg por usuario
- Groq LPU: ~600 tokens/seg por usuario
- Cerebras: ~2,000 tokens/seg por usuario
- Taalas HC1: ~17,000 tokens/seg por usuario
La historia de costos es igualmente dramática. Según el análisis de Benjamin Marie en Kaitchup, el HC1 entrega inferencia a aproximadamente $0.0075 por millón de tokens — comparado con $0.10/M para Cerebras y $2-$15/M para APIs en la nube como OpenAI y Anthropic. Eso es 13x más barato que la siguiente opción de hardware más económica y hasta 2,000x más barato que las APIs en la nube.
¿El compromiso? Flexibilidad. El HC1 solo puede ejecutar Llama 3.1 8B. No puedes cargar un modelo diferente en él. Es un chip de un solo modelo.
Pero ahí es donde entra LoRA.
Por Qué el Soporte LoRA en Silicio Hardwired Importa
Aquí está el detalle al que todo constructor debería prestar atención: a pesar de que el modelo base está físicamente grabado en transistores, el HC1 soporta fine-tuning Low-Rank Adaptation (LoRA).
Los adaptadores LoRA son capas de personalización ligeras — típicamente 50-200MB — que se sientan encima de un modelo base y lo especializan para un dominio o tarea específica. En el HC1, los pesos base de Llama 3.1 8B están hardwired para velocidad, mientras que los pesos del adaptador LoRA se cargan en SRAM on-chip para flexibilidad.
Esto significa:
- Un chip, muchas especializaciones. Carga un adaptador LoRA legal y el chip ejecuta un AI legal. Intercambia por un LoRA médico y ejecuta un AI clínico. El modelo base nunca cambia; la capa de especialización sí.
- Inferencia de modelo ajustado a velocidad de hardware. Tu modelo ajustado específico del dominio corre a 17,000 tokens/seg, no solo el modelo base genérico.
- El modelo multi-tenant funciona en silicio. ¿Agencias ejecutando adaptadores LoRA por cliente en infraestructura base compartida? Eso es exactamente lo que el HC1 permite, pero a nivel de hardware.
Esto es un cambio de paradigma. LoRA fue originalmente diseñado como una técnica de entrenamiento eficiente en memoria — una forma de ajustar modelos grandes sin el costo del fine-tuning completo. Ahora se está convirtiendo en una interfaz de despliegue de hardware. El formato del adaptador no es solo cómo entrenas; es cómo despliegas en silicio dedicado.
La Economía de Modelos Ajustados Hardwired
Hagamos las matemáticas para un escenario real.
Una agencia de AI ejecutando 15 chatbots de clientes, cada uno con un adaptador LoRA diferente:
| Despliegue | Costo mensual | Tokens/seg | Privacidad |
|---|---|---|---|
| OpenAI GPT-4o (15 clientes) | $4,200+ | 50-100 | Datos enviados a OpenAI |
| 8B auto-hospedado en GPU | $150-400 | 20-50 | Control total |
| Taalas HC1 + 15 adaptadores LoRA | Dramáticamente menor | 17,000 | Control total |
El HC1 no está disponible para compra on-premise aún — Taalas actualmente ofrece inferencia como un servicio API en beta en chatjimmy.ai. Pero la dirección es clara: hardware dedicado para modelos ajustados está pasando de la teoría a la producción.
El Paralelo Histórico: CPUs, Smartphones y Chips de AI
Esto ha pasado antes. Múltiples veces.
En 1946, ENIAC llenaba una habitación y realizaba 5,000 operaciones por segundo. Para 1971, el microprocesador 4004 de Intel puso cómputo comparable en un chip del tamaño de una uña. Para 2007, el iPhone puso una computadora completa en el bolsillo de todos.
Cada generación de hardware no solo hizo las tareas existentes más rápidas — creó categorías de uso completamente nuevas. Los mainframes sirvieron a las empresas. Las PCs sirvieron a los trabajadores del conocimiento. Los smartphones sirvieron a todos.
La inferencia de AI va en la misma trayectoria:
- GPUs de centro de datos (2020-2024): AI como servicio en la nube
- Inferencia edge (2024-2026): AI en hardware local (Ollama, llama.cpp, LM Studio)
- Silicio dedicado (2026+): AI hardwired en chips diseñados específicamente
- On-device (siguiente): AI embebido en cada dispositivo
El HC1 está en la etapa 3. Y así como el microprocesador necesitó software (sistemas operativos, aplicaciones) para ser útil más allá del cómputo crudo, el silicio de AI dedicado necesita modelos ajustados para ser útil más allá de ejecutar un chatbot genérico.
El fine-tuning es la capa de software que hace valioso al hardware de AI dedicado.
Lo Que Viene de Taalas
Taalas ha delineado una hoja de ruta clara:
- Primavera 2026: Modelo de razonamiento de tamaño medio en la plataforma HC1 — llevando cadena de pensamiento y razonamiento multi-paso al silicio dedicado
- Invierno 2026: LLM frontier en la plataforma HC2 — un chip de segunda generación con mayor densidad y ejecución más rápida
- Generaciones futuras: El silicio de segunda generación usará formatos estándar de punto flotante de 4 bits, abordando los compromisos de calidad de la cuantización agresiva de 3 bits del HC1
La empresa afirma que pueden convertir un nuevo modelo en silicio funcional en aproximadamente dos meses. Si eso se mantiene, cada lanzamiento importante de modelo open-weight se convierte en un chip potencial de la serie HC.
Lo Que Esto Significa para los Constructores Ahora Mismo
No necesitas esperar a que Taalas envíe hardware a tu puerta para actuar sobre esta señal.
La conclusión es estratégica: Los fabricantes de hardware están incorporando soporte LoRA en su silicio porque ven el fine-tuning como la interfaz de despliegue del futuro. Si estás construyendo AI en tu producto, tu flujo de trabajo o las ofertas de tu agencia, el modelo que despliegas debe estar ajustado para tu dominio.
Esto es lo que debes hacer ahora:
-
Ajusta modelos open-weight hoy. Llama, Qwen, Gemma, Phi — elige el modelo base que se ajuste a tu tarea. El adaptador LoRA ajustado que crees hoy funcionará en GPUs ahora y en silicio dedicado después.
-
Exporta en formatos portables. GGUF para inferencia local (Ollama, llama.cpp, LM Studio). Adaptadores LoRA en formatos estándar. No te encierres en un solo objetivo de despliegue.
-
Piensa en adaptadores, no en modelos monolíticos. Un modelo base + múltiples adaptadores LoRA = una inversión de entrenamiento que sirve a muchos clientes, muchos casos de uso, muchos objetivos de despliegue.
-
Comienza con el caso de uso, no con el hardware. Ya sea que despliegues en una GPU, un dispositivo edge o silicio dedicado, el modelo ajustado es la constante. El hardware es la variable.
La Ventana de Fine-Tuning Está Abierta
Taalas es una señal en una tendencia más amplia. Se proyecta que el hardware de AI edge alcance $59 mil millones para 2030. Se espera que las cargas de trabajo de inferencia representen dos tercios de todo el cómputo de AI para fines de 2026. Y los modelos que correrán en todo este hardware necesitan estar ajustados para dominios específicos para ser útiles.
Los equipos que aprendan a ajustar ahora — que construyan los datasets, entrenen los adaptadores y validen la calidad — tendrán modelos listos para producción cuando el hardware los alcance. Los que esperen estarán empezando desde cero mientras sus competidores ya están desplegados.
Ertas hace el fine-tuning accesible para constructores que no tienen experiencia en ML. Sube un dataset, ajusta visualmente, exporta como GGUF o adaptador LoRA, despliega en cualquier lugar. El modelo que ajustas hoy es el modelo que corre en el hardware de mañana.
Este artículo referencia información del anuncio de Taalas y la página de producto, con análisis adicional de WCCFTech, EE Times, Data Center Dynamics y Kaitchup.
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading
Por qué las empresas de hardware están incorporando soporte de LoRA en sus chips
Taalas, Apple, Qualcomm y otros están agregando soporte de adaptadores LoRA a su silicio de IA. No es coincidencia — LoRA se está convirtiendo en la interfaz estándar entre modelos ajustados y hardware de inferencia.
LoRA en silicio: cómo el hardware está convirtiendo el fine-tuning en ciudadano de primera clase
Desde el HC1 de Taalas hasta QVAC Fabric LLM de Tether Data, los fabricantes de hardware están incorporando soporte LoRA directamente en sus plataformas. El fine-tuning ya no es solo una técnica de entrenamiento: se está convirtiendo en una interfaz de despliegue de hardware.
Taalas vs Nvidia vs Groq vs Cerebras: Hardware de Inferencia AI Comparado (2026)
Una comparación detallada del hardware de inferencia AI en 2026: Taalas HC1 (modelo en silicio), Nvidia H200/B200 (GPU general), Groq LPU, Cerebras a escala de wafer y SambaNova. Rendimiento, costo, flexibilidad y soporte de fine-tuning comparados.