
Taalas HC1:硬連線 Llama 晶片對微調的意義
一家加拿大新創公司剛剛將 Llama 3.1 8B 燒錄進矽晶片,實現每秒 17,000 個 token,每百萬 token 成本 0.0075 美元——比 Nvidia 的 H200 快達 74 倍。HC1 的 LoRA 支援表明微調正在成為硬體層面的能力。
一家名為 Taalas 的加拿大新創公司剛剛做了一件聽起來不可能的事:他們取了 Meta 的 Llama 3.1 8B 模型,直接硬連線進一顆晶片。不是載入 GPU,不是透過軟體執行環境運行,而是將模型權重蝕刻進 815 平方毫米晶片上的 530 億個電晶體中。
結果?每位用戶每秒 17,000 個 token。這比市場上任何其他產品快大約 8–74 倍,包括 Nvidia 的 H200、Groq 的 LPU 和 Cerebras 的晶圓級引擎。
但速度不是最有趣的部分。最有趣的是,儘管是硬連線的,HC1 仍支援 LoRA 微調。這改變了我們思考微調在 AI 技術棧中角色的一切。
Taalas 實際建立了什麼
HC1 是一個在台積電 6nm 製程上製造的特定應用積體電路(ASIC)。Taalas 沒有使用通用算力從記憶體運行模型權重(這是每個 GPU 的做法),而是將 Llama 3.1 8B 架構直接編譯進矽晶片中。
關鍵規格:
| 規格 | HC1 |
|---|---|
| 模型 | Llama 3.1 8B(硬連線) |
| 製程 | 台積電 6nm |
| 晶片大小 | 815mm² |
| 電晶體數 | 530 億 |
| 吞吐量 | 每位用戶約 17,000 token/秒 |
| 功耗 | 2.5kW 伺服器 |
| 量化 | 自訂 3-bit 基礎 + 6-bit 參數 |
| LoRA 支援 | 是(可配置的 adapter) |
| 上下文視窗 | 可配置 |
該公司於 2026 年 2 月在融資 1.69 億美元(使其總額達到 2.19 億美元)後宣布進入公開模式。他們用一個 24 人的團隊花費了約 3,000 萬美元——並建造出了可運行的矽晶片。
 來源:Taalas。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
來源:Taalas。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
效能差距令人震驚
基準數字將 HC1 置於與現有推論硬體截然不同的類別:
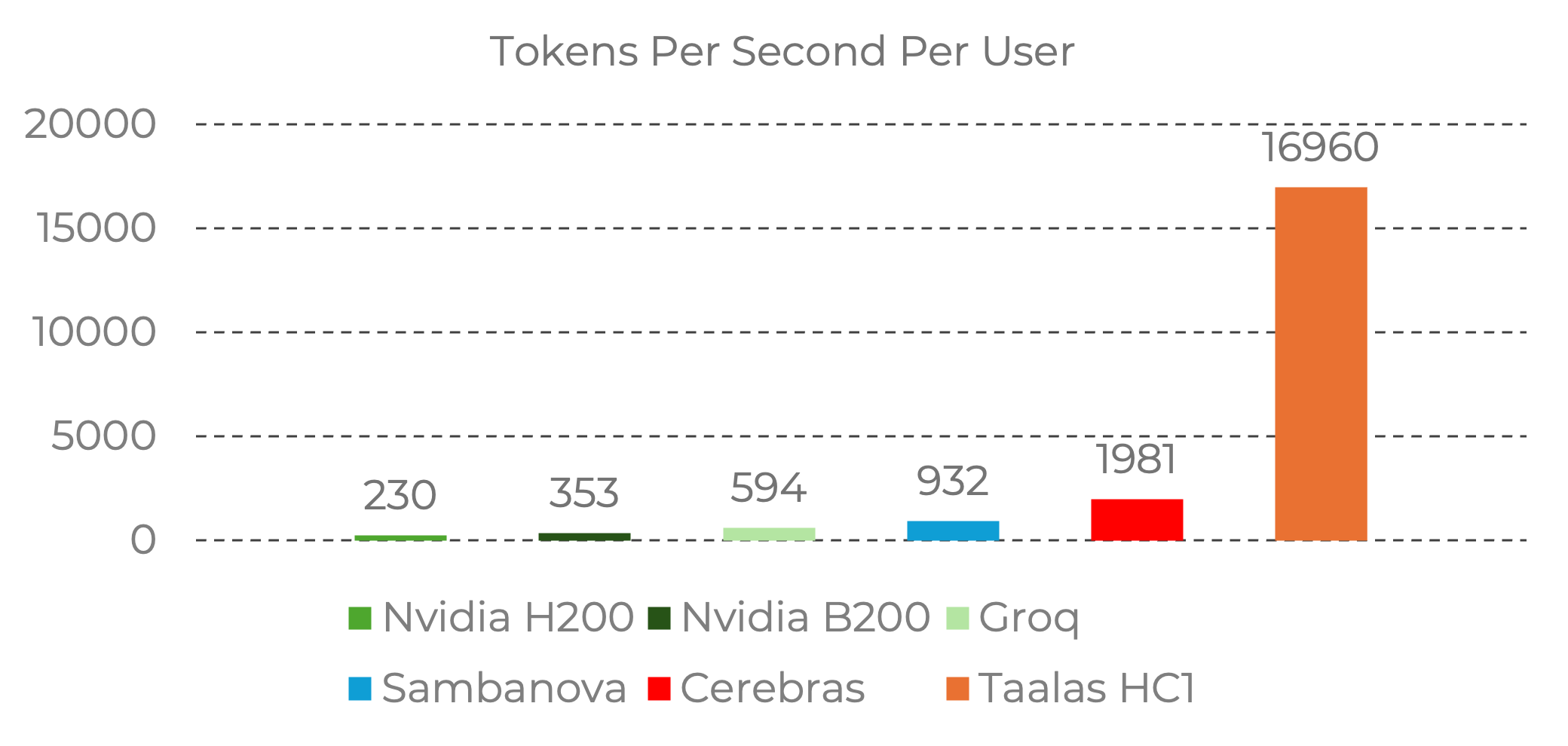 來源:Taalas。基準數據來自 Nvidia 官方基準和 Artificial Analysis 服務商數據。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
來源:Taalas。基準數據來自 Nvidia 官方基準和 Artificial Analysis 服務商數據。圖片轉載用於編輯評論。所有權利屬於 Taalas Inc.
為這些數字提供背景:
- Nvidia H200:每位用戶約 230 token/秒
- Groq LPU:每位用戶約 600 token/秒
- Cerebras:每位用戶約 2,000 token/秒
- Taalas HC1:每位用戶約 17,000 token/秒
成本故事同樣戲劇性。根據 Kaitchup 的 Benjamin Marie 的分析,HC1 以約 每百萬 token 0.0075 美元的成本提供推論——相比 Cerebras 的 0.10 美元/百萬 token 和 OpenAI、Anthropic 等雲端 API 的 2–15 美元/百萬 token。這比次便宜的硬體選項便宜 13 倍,比雲端 API 便宜最多 2,000 倍。
代價是什麼?靈活性。HC1 只能運行 Llama 3.1 8B。您無法在上面載入不同的模型。它是一顆單模型晶片。
但這正是 LoRA 發揮作用的地方。
為何硬連線矽晶片上的 LoRA 支援很重要
以下是應��讓每位開發者注意的細節:儘管基礎模型被實體燒入電晶體,HC1 仍支援低秩自適應(LoRA)微調。
LoRA adapter 是輕量級的定制層——通常 50–200MB——位於基礎模型之上,專門用於特定領域或任務。在 HC1 上,基礎 Llama 3.1 8B 權重為速度而硬連線,而 LoRA adapter 權重載入片上 SRAM 以獲得靈活性。
這意味著:
- 一顆晶片,多種專業化。 載入法律 LoRA adapter,晶片就能運行法律 AI。換入醫療 LoRA,就能運行臨床 AI。基礎模型從不改變;專業化層會改變。
- 硬體速度的微調推論。 您的領域專屬微調模型以 17,000 token/秒運行,而不只是通用基礎模型。
- 多租戶模型在矽晶片層面實現。 代理公司在共享基礎設施上為每個客戶運行 LoRA adapter?這正是 HC1 在硬體層面實現的。
這是一個典範轉移。LoRA 最初被設計為記憶體高效的訓練技術——一種無需全量微調成本即可微調大型模型的方式。現在它正在成為硬體部署介面。adapter 格式不只是訓練的方式;它是在專用矽晶片上部署的方式。
硬連線微調模型的經濟學
讓我們對真實場景進行計算。
一家運營 15 個客戶聊天機器人的 AI 代理公司,每個使用不同的 LoRA adapter:
| 部署方式 | 每月成本 | Token/秒 | 隱私 |
|---|---|---|---|
| OpenAI GPT-4o(15 個客戶) | 4,200 美元以上 | 50–100 | 資料傳送至 OpenAI |
| GPU 自行託管 8B | 150–400 美元 | 20–50 | 完全控制 |
| Taalas HC1 + 15 個 LoRA adapter | 大幅更低 | 17,000 | 完全控制 |
HC1 目前尚不�可本地購買——Taalas 目前在 chatjimmy.ai 提供推論作為測試版 API 服務。但方向很清晰:用於微調模型的專用硬體正從理論走向生產。
歷史類比:CPU、智慧型手機和 AI 晶片
這一切以前發生過,多次了。
1946 年,ENIAC 佔據整個房間,每秒執行 5,000 次運算。到 1971 年,Intel 的 4004 微處理器將相當的算力放在指甲大小的晶片上。到 2007 年,iPhone 將完整的電腦放進了每個人的口袋。
每一代硬體不只是讓現有任務更快——它創造了全新的使用類別。主機服務企業,個人電腦服務知識工作者,智慧型手機服務所有人。
AI 推論處於同樣的發展軌跡:
- 資料中心 GPU(2020–2024 年):AI 作為雲端服務
- 邊緣推論(2024–2026 年):本地硬體上的 AI(Ollama、llama.cpp、LM Studio)
- 專用矽晶片(2026 年起):AI 硬連線進專用晶片
- 設備上(��下一步):AI 嵌入每個設備
HC1 處於第三階段。就像微處理器需要軟體(作業系統、應用程式)才能在原始算力之外變得有用,專用 AI 矽晶片需要微調模型才能在運行通用聊天機器人之外變得有用。
微調是使專用 AI 硬體有價值的軟體層。
Taalas 的下一步
Taalas 已概述了清晰的路線圖:
- 2026 年春季:HC1 平台上的中等規模推理模型——將思維鏈和多步推理帶入專用矽晶片
- 2026 年冬季:HC2 平台上的前沿 LLM——具有更高密度和更快執行速度的第二代晶片
- 未來世代:第二代矽晶片將使用標準 4-bit 浮點格式,解決 HC1 激進 3-bit 量化帶來的品質妥協
該公司聲稱可以在大約兩個月內將新模型轉換為可運行的矽晶片。如果成立,每個主要的開放權重模型發布都將成為潛在的 HC 系列晶片。
這對開發者現在意味著什麼
您不需要等待 Taalas 向您的門口運送硬體才能根據這個訊號採取行動。
要點是戰略性的: 硬體供應商在其矽晶片中內建 LoRA 支援,是因為他們將微調視為未來的部署介面。如果您在產品、工作流程或代理公司的服務中構建 AI,您部署的模型應該針對您的領域進行微調。
現在要做的事:
-
今天在開放權重模型上微調。 Llama、Qwen、Gemma、Phi——選擇適合您任務的基礎模型。您今天創建的微調 LoRA adapter 現在可以在 GPU 上工作,以後也可以在專用矽晶片上工作。
-
以可攜格式匯出。 用於本地推論的 GGUF(Ollama、llama.cpp、LM Studio)。標準格式的 LoRA adapter。不要將自己鎖定在一個部署目標上。
-
以 adapter 而非整體模型思考。 一個基礎模型 + 多個 LoRA adapter = 一次訓練投資,服務多個客戶、多個使用場景、多個部署目標。
-
從使用場景開始,而非硬體。 無論您在 GPU、邊緣設備還是專用矽晶片上部署,微調後的模型是常數。硬體是��變數。
微調視窗已打開
Taalas 是更廣泛趨勢中的一個訊號。邊緣 AI 硬體預計到 2030 年達到 590 億美元。預計到 2026 年底,推論工作負載將占所有 AI 算力的三分之二。而將在所有這些硬體上運行的模型需要針對特定領域進行微調才能有用。
現在學習微調的團隊——建立資料集、訓練 adapter、驗證品質——將在硬體趕上時擁有生產就緒的模型。等待的人將在競爭對手已部署時從零開始。
Ertas 讓沒有 ML 專業知識的開發者可以進行微調。上傳資料集,視覺化微調,匯出為 GGUF 或 LoRA adapter,隨處部署。您今天微調的模型就是明天硬體上運行的模型。
本文參考了 Taalas 公告 和產品頁面的資訊,以及來自 WCCFTech、EE Times、Data Center Dynamics 和 Kaitchup 的額外分析。
Ship AI that runs on your users' devices.
Free plan with 30 credits/mo, no card required. Paid plans from $25/mo USD.
Keep reading

為何硬體公司將 LoRA 支援內建到晶片中
Taalas、Apple、Qualcomm 等公司正在將 LoRA 適配器支援加入其 AI 晶片。這不是巧合——LoRA 正在成為微調模型與推論硬體之間的標準介面。

矽晶片上的 LoRA:硬體如何讓微調成為一等公民
從 Taalas 的 HC1 到 Tether Data 的 QVAC Fabric LLM,硬體廠商正在將 LoRA 支援直接整合到其平台中。微調不再只是一種訓練技術——它正在成為一種硬體部署介面。

Taalas vs Nvidia vs Groq vs Cerebras:AI 推論硬體比較(2026 年)
2026 年 AI 推論硬體詳細比較:Taalas HC1(模型燒入矽晶片)、Nvidia H200/B200(通用 GPU)、Groq LPU、Cerebras 晶圓級引擎和 SambaNova。效能、成本、靈活性和微調支援的全面比較。